目录
TPCC测试方法—benchmarksql
一、环境准备
操作系统:openEuler 22.03 x86_64
前提条件:openGauss已经编译并安装成功,gsql可以正常连接数据库
需要的依赖:ant
bashsudo dnf install ant
1.1 创建新用户
连接数据库gsql -r -p 5432,创建远程连接用户tpcc,并授予SYSADMIN管理员权限。
sqlCREATE USER tpcc PASSWORD 'Tpcc@123';
ALTER USER tpcc SYSADMIN;
create database tpccdb;
这里用户tpcc用于做benchmaksql的测试用户,测试数据库为tpccdb,该用户赋予管理员权限。
1.2 安装BenchMarkSQL
- 下载并上传BenchMarkSQL 下载BenchMarkSQL源码包,并上传和解压。 下载地址:https://sourceforge.net/projects/benchmarksql/
- 将benchmarksql-5.0.zip 压缩包上传至服务器上并解压。 解压
bashunzip benchmarksql-5.0.zip
1.3 下载openGauss JDBC驱动
BenchMarkSQL使用JDBC驱动包,连续各种数据库,故需要下载openGauss对应版本的JDBC驱动包。
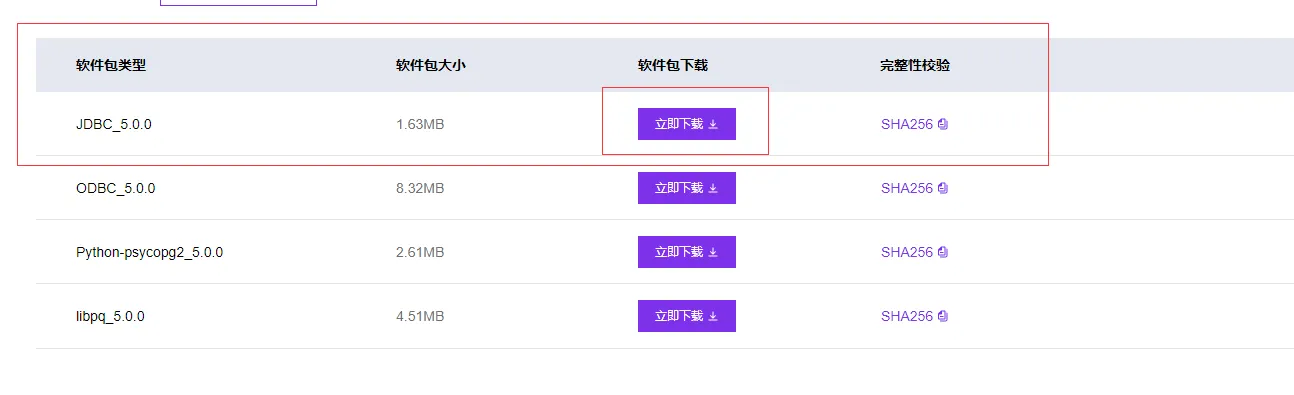
上传openGauss-5.0.0-JDBC.tar.gz到benchmarksql-5.0/lib/postgres/路径,并解压。openGauss的JDBC驱动解压后有两个jar包(postgresql.jar和opengauss-jdbc-5.0.0.jar),解压前需要将benchmarksql-5.0/lib/postgres/路径下原有的postgresql.jar文件删除,然后将解压后的两个jar包复制到benchmarksql-5.0/lib/postgres/路径下。
bashcd ~/benchmarksql-5.0/lib/postgres/
# 删除原有的postgresql.jar
mv postgresql.jar postgresql.jar.bak
tar -xzvf openGauss-5.0.0-JDBC.tar.gz
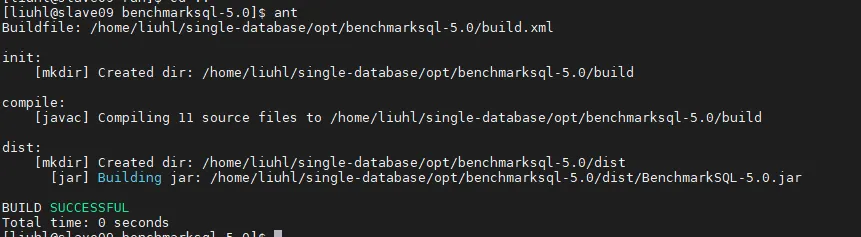
1.4 编译BenchMarkSQL
bashcd ~/benchmarksql-5.0
ant
二、修改配置
2.1 创建openGauss的props文件
benchmarksql-5.0/run/ 路径下的 Props.*为BenchMarkSQL的测试配置文件,在生成测试数据和执行测试时,BenchMarkSQL都会使用该文件。
可复制已有的props.*模板,修改为可用于openGauss的配置文件。
bashcd ~/benchmarksql-5.0/run
cp props.pg props.opengauss
nano props.opengauss
写入如下信息,具体配置根据注释修改
bashdb=postgres
driver=org.postgresql.Driver
// 数据库的ip、端口和数据库名
conn=jdbc:postgresql://127.0.0.1:33000/tpccdb
// 前面创建的数据库用户名
user=tpcc
// 数据库密码
password=Tpcc@123
// 数据仓数量
warehouses=100
// 数据创建工作线程数
loadWorkers=25
// 测试过程的连接终端数(并发数)
terminals=100
// 每个终端运行的事务数,该参数与下面的runMins是两种测试策略,所以设置每个终端运行的事务数之后测试时间必须设置为0
runTxnsPerTerminal=0
// 测试时间,如果设置了测试时间,那么runTxnsPerTerminal参数必须为0
runMins=15
//Number of total transactions per minute,0代表无限制
limitTxnsPerMin=0
//Set to true to run in 4.x compatible mode. Set to false to use the
//entire configured database evenly.
terminalWarehouseFixed=false
//The following five values must add up to 100
//The default percentages of 45, 43, 4, 4 & 4 match the TPC-C spec
newOrderWeight=45
paymentWeight=43
orderStatusWeight=4
deliveryWeight=4
stockLevelWeight=4
// Directory name to create for collecting detailed result data.
// Comment this out to suppress.
resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tS
osCollectorScript=./misc/os_collector_linux.py
osCollectorInterval=1
// 服务器ssh连接的用户名和地址(Tpcc测试机必须跟数据库服务器设置ssh互信)
osCollectorSSHAddr=shuaikangzhou@127.0.0.1
// 监控的磁盘和网卡,可以设置多个,用空格隔开,网卡命名方式net_xxx,xxx是设备名,磁盘命名方式 blk_xxx,xxx是磁盘名
osCollectorDevices=net_eth4 blk_sdc
- 网卡查看方式
bashifconfig
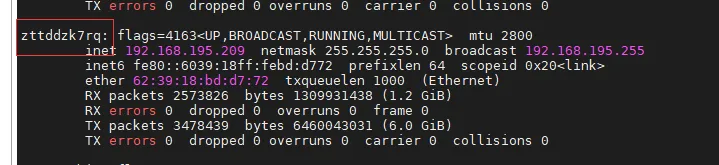
这里网卡显示为zttddzk7rq,全拼写成 net_zttddzk7rq
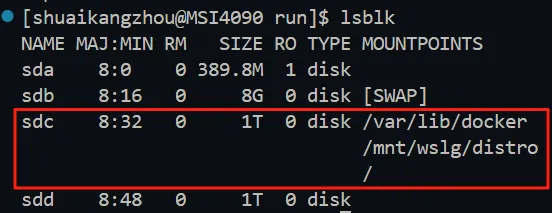
- 磁盘查看方式
bashlsblk
选择数据库数据存储目录所挂载的磁盘,这里显示整个根目录(/)都挂载到sdc磁盘了,所以磁盘名为blk_sdc
- 如果服务器ssh用的不是默认端口需要修改benchmarksql-5.0/src/OSCollector/OSCollector.java文件修改之后需要重新编译
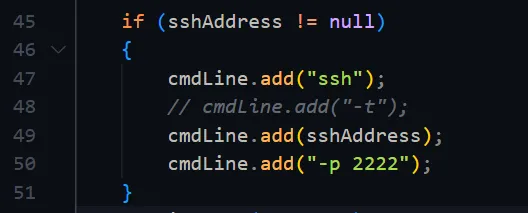
bash if (sshAddress != null)
{
cmdLine.add("ssh");
// cmdLine.add("-t");
cmdLine.add(sshAddress);
cmdLine.add("-p 2222");
}
三、开始测试
3.1 生成测试数据。
bashcd ~/benchmarksql-5.0/run
./runDatabaseBuild.sh props.opengauss
3.2 压力测试
bash./runBenchmark.sh props.opengauss
测试完成之后会在当前目录下生成测试结果,位于./my_result_xxxx-xx-xx_xxxx文件夹下
3.3 生产压测报告
该操作需要安装R语言的环境,生成报告之前需要检查一下R语言环境是否存在。
bashR --version
如果没有R语言环境需要手动下载源码并编译
- 生成报告
bashcd benchmarksql-5.0/run
./generateGraphs.sh my\_result\_2023-xx-xx\_xxxxxx
./generateReport.sh my\_result\_2023-xx-xx\_xxxxxx
- 生成图片
- 生成报告
下载my_result_2023-05-04_142051文件夹到桌面,使用浏览器打开文件夹内的report.html文件
3.4 清理数据
该操作会将数据库仓库全部删除,再次测试需要重新创建数据
bash./runDatabaseDestroy.sh props.opengauss
四、其他说明
4.1 修改openGauss监听地址
默认配置只能本机连接数据库,为了不影响性能,TPCC客户端尽量不要跟数据库在同一台机器上,此时需要修改数据库的配置以便局域网内的其他设备可以连接。
找到数据库的数据目录
- 编辑
pg_hba.conf配置文件 添加连接配置
bashhost all all 172.19.0.0/16 sha256
- 编辑
postgresql.conf文件 编辑配置文件,将:
propertieslisten_addresses = 'localhost' # 或默认只监听127.0.0.1
修改为:
propertieslisten_addresses = '*' # 允许监听所有网络接口(包括局域网IP)
也可以指定具体的局域网 IP(如172.19.0.209),但*更灵活。
- 重启数据库
4.2 日志配置
benchmarksql-5.0/run/log4j.properties文件是日志文件的配置信息,可以修改这个配置将不同的日志输出到不同的文件里,方便后续解析日志信息
plain# log4j.rootLogger=TRACE, CONSOLE, E, T log4j.rootLogger=DEBUG, CONSOLE, E, FILE # 日志记录器的名称 log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender log4j.appender.CONSOLE.Threshold=INFO log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout log4j.appender.CONSOLE.layout.ConversionPattern= %d{HH:mm:ss,SSS} [%t] %-5p %x %C{1} : %m%n log4j.appender.E=org.apache.log4j.RollingFileAppender log4j.appender.E.Threshold=WARN log4j.appender.E.File=benchmarksql-error.log log4j.appender.E.MaxFileSize=100MB log4j.appender.E.MaxBackupIndex=1 log4j.appender.E.layout=org.apache.log4j.PatternLayout log4j.appender.E.layout.ConversionPattern= %d{HH:mm:ss,SSS} [%t] %-5p %x %C{1} : %m%n log4j.appender.T=org.apache.log4j.FileAppender log4j.appender.T.Threshold=TRACE log4j.appender.T.File=benchmarksql-trace.log log4j.appender.T.append=false log4j.appender.T.layout=org.apache.log4j.PatternLayout log4j.appender.T.layout.ConversionPattern= %d{HH:mm:ss,SSS} [%t] %-5p %x %C{1} : %m%n # 文件输出配置 log4j.appender.FILE=org.apache.log4j.FileAppender # 将日志写入文件里 log4j.appender.FILE.Threshold=DEBUG # 日志的级别 log4j.appender.FILE.File=benchmarksql-debug.log # 日志文件名 log4j.appender.FILE.DatePattern='.'yyyyMMdd_HHmmss log4j.appender.FILE.Append=false # true:不清空文件直接追加到文件末尾,false:先清空文件再写日志 log4j.appender.FILE.layout=org.apache.log4j.PatternLayout log4j.appender.FILE.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c - %m%n
4.3 统计内存占用
下面的配置可以将debug日志输出到benchmarksql-debug.log文件里
plain# 文件输出配置 log4j.appender.FILE=org.apache.log4j.FileAppender # 将日志写入文件里 log4j.appender.FILE.Threshold=DEBUG # 日志的级别 log4j.appender.FILE.File=benchmarksql-debug.log # 日志文件名 log4j.appender.FILE.DatePattern='.'yyyyMMdd_HHmmss log4j.appender.FILE.Append=false # true:不清空文件直接追加到文件末尾,false:先清空文件再写日志 log4j.appender.FILE.layout=org.apache.log4j.PatternLayout log4j.appender.FILE.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c - %m%n
修改benchmarksql-5.0/src/client/jTPCC.java的最后一个函数,在倒数第三行添加log.debug(informativeText);就能将统计信息写入日志里
javasynchronized private void updateStatusLine()
{
long currTimeMillis = System.currentTimeMillis();
if(currTimeMillis > sessionNextTimestamp)
{
StringBuilder informativeText = new StringBuilder("");
Formatter fmt = new Formatter(informativeText);
double tpmC = (6000000*fastNewOrderCounter/(currTimeMillis - sessionStartTimestamp))/100.0;
double tpmTotal = (6000000*transactionCount/(currTimeMillis - sessionStartTimestamp))/100.0;
sessionNextTimestamp += 1000; /* update this every seconds */
fmt.format("Term-00, Running Average tpmTOTAL: %.2f", tpmTotal);
/* XXX What is the meaning of these numbers? */
recentTpmC = (fastNewOrderCounter - sessionNextKounter) * 12;
recentTpmTotal= (transactionCount-sessionNextKounter)*12;
sessionNextKounter = fastNewOrderCounter;
fmt.format(" Current tpmTOTAL: %d", recentTpmTotal);
long freeMem = Runtime.getRuntime().freeMemory() / (1024*1024);
long totalMem = Runtime.getRuntime().totalMemory() / (1024*1024);
fmt.format(" Memory Usage: %dMB / %dMB ", (totalMem - freeMem), totalMem);
System.out.print(informativeText);
log.debug(informativeText);
for (int count = 0; count < 1+informativeText.length(); count++)
System.out.print("\b");
}
}
修改之后需要重新编译
javacd bencmarksql-5.0/
ant
可以写一个简单的脚本解析日志文件的内存占用情况
java2025-09-16 12:35:27 DEBUG jTPCC - Term-00, Running Average tpmTOTAL: 59875.17 Current tpmTOTAL: 39209184 Memory Usage: 333MB / 915MB
新建一个Python文件:run/misc/memory.py 写入下面内容
pythonimport re
import pandas as pd
import matplotlib.pyplot as plt
import os
import sys
def main():
# 检查命令行参数
if len(sys.argv) != 2:
print("用法: python memory_usage_plot.py <日志文件路径>")
sys.exit(1)
# 获取命令行输入的日志文件路径
log_file = sys.argv[1]
# 验证文件是否存在
if not os.path.exists(log_file):
print(f"错误: 文件 '{log_file}' 不存在")
sys.exit(1)
# 用来存储数据
timestamps = []
used_mem = []
total_mem = []
# 匹配日志中时间和 Memory Usage
pattern = re.compile(r"(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}).*Memory Usage: (\d+)MB / (\d+)MB")
with open(log_file, "r") as f:
for line in f:
match = pattern.search(line)
if match:
timestamps.append(match.group(1))
used_mem.append(int(match.group(2)))
total_mem.append(int(match.group(3)))
if not timestamps:
print("警告: 未在日志文件中找到任何内存使用记录")
sys.exit(0)
# 构建 DataFrame
df = pd.DataFrame({
"timestamp": pd.to_datetime(timestamps),
"used_mb": used_mem,
"total_mb": total_mem
})
# 计算相对时间(分钟),从0开始
start_time = df["timestamp"].iloc[0]
df["minutes_since_start"] = (df["timestamp"] - start_time).dt.total_seconds() / 60
# 绘制曲线
plt.figure(figsize=(12, 6))
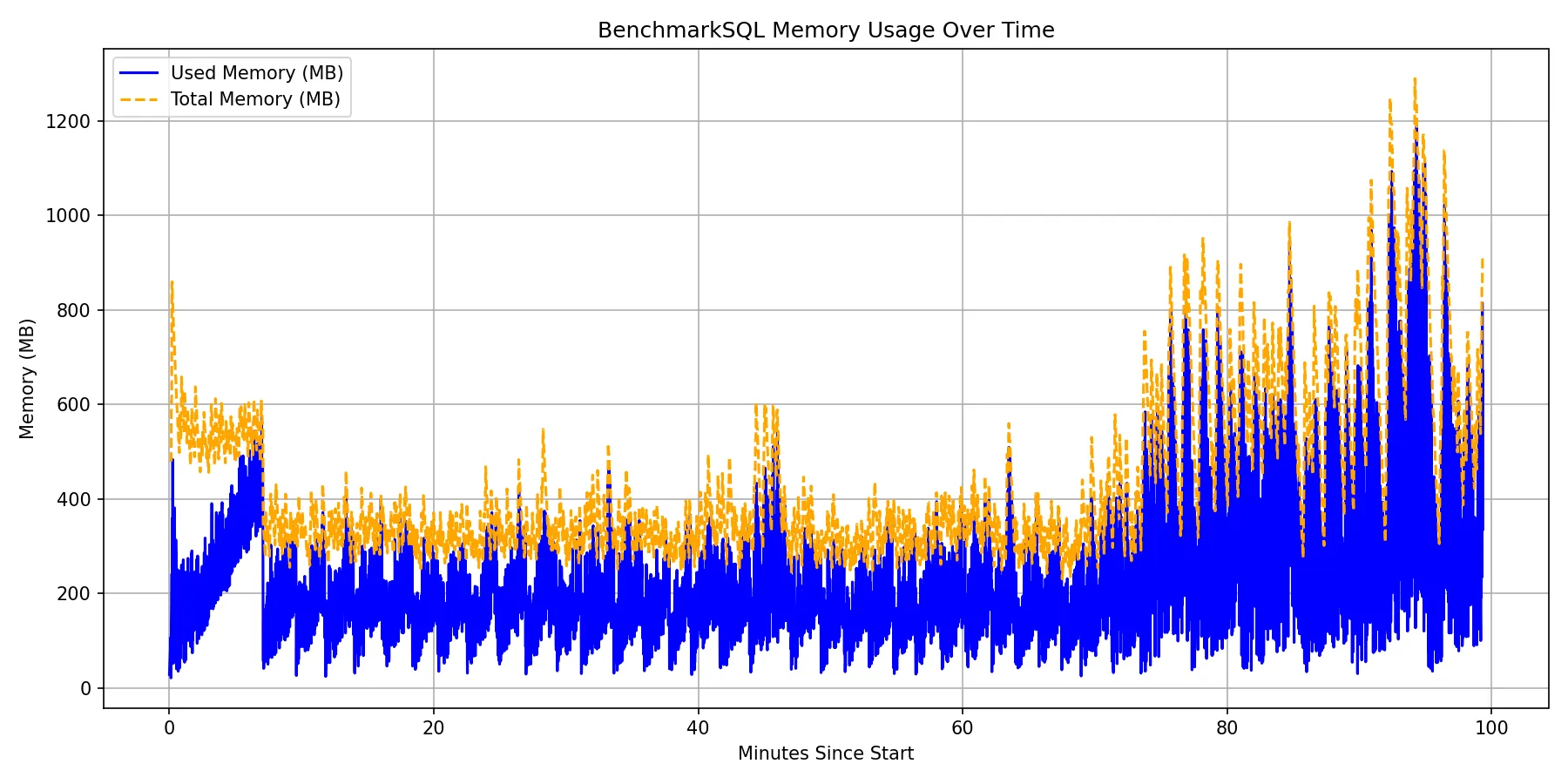
plt.plot(df["minutes_since_start"], df["used_mb"], label="Used Memory (MB)", color="blue")
plt.plot(df["minutes_since_start"], df["total_mb"], label="Total Memory (MB)", color="orange", linestyle="--")
plt.xlabel("Minutes Since Start")
plt.ylabel("Memory (MB)")
plt.title("BenchmarkSQL Memory Usage Over Time")
plt.legend()
plt.grid(True)
plt.tight_layout()
# 获取日志文件所在目录
log_dir = os.path.dirname(log_file)
# 构建图片保存路径(与日志文件同目录)
image_path = os.path.join(log_dir, "memory_usage_curve.png")
# 保存图片
plt.savefig(image_path, dpi=150)
print(f"曲线已保存为 {image_path}")
if __name__ == "__main__":
main()
运行脚本:
pythonpython ./misc/memory benchmark-debug.log
此时就会在benchmark-debug.log所在的目录下生成一个内存占用图(memory_usage_curve.png)
五、自动化测试脚本
bashsh runTpcc.sh -a -c -w 200 -n 3
5.1 参数说明
- -a: 开启ATF,默认不开启
- -c: 重建数据仓,默认不重建(相关细节在server.sh里)
- -w k: 数据仓大小(仅支持200、400、1000),默认为200
- -n k: 连续测试k次,默认为1
- -m jvm_max_mem: 限制JVM最大堆内存,默认不限制
5.2 前置准备
- 修改props.* 文件里的连接参数
- 打开server.sh,根据教程修改下面几个变量
bash# 远程服务器信息 - 请根据实际情况修改以下信息
remote_server="zhousk@192.168.200.209"
# 远程服务器用户名和主机地址,例如:root@192.168.1.100,需要与本机设置互信
db_dir="/mnt/nvme2n1/zhousk/data/data_n1"
TABSPACE2_DIR="/mnt/nvme3n1/zhousk/data/data_n1"
TABSPACE3_DIR="/mnt/nvme4n1/zhousk/data/data_n1"
XLOG_DIR="/mnt/raid0/zhousk/data/data_n1/pg_xlog"
backup_dir="/mnt/nvme4n1/zhousk/backup/${warehouses}w"
-
benchmarksql测试机与数据库服务器配置互信
-
创建原始数据,根据教程分别生成仓数为100、200、1000的数据库,分别将整个数据库目录备份到backup_dir文件夹下
例如:100仓的数据库目录为/mnt/nvme4n1/zhousk/backup/100w
-
数据分盘,在不同硬盘上分别创建以下四个文件夹并把实际目录写到server.sh文件里
- db_dir:测试数据库数据目录
- TABSPACE2_DIR:数据表空间的软连接地址(在其他磁盘上)
- TABSPACE3_DIR:另一个数据表空间的软连接地址
- XLOG_DIR:xlog软连接地址
PS: 为避免数据干扰每次测试前都会,删除四个文件夹下的数据然后将对应仓数的备份数据复制到db_dir下,然后创建四个软连接将数据分散到多个硬盘上
5.3 查看报告
使用runTpcc.sh之后每次测试完成之后都会在结果文件夹下生成一个 report.html, 需要将整个文件夹下载到本地才能查看,比较麻烦。
app.py 提供了一个网络服务器,可以通过浏览器查看测试报告
5.4 使用方法
bashpython3 app.py
在浏览器打开 http://ip:8000 (ip为benchmarksql的ip地址)来查看报告
5.5 源代码
本文作者:司小远
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!