目录
每次在12306抢票时,你有没有过这样的好奇:从冰天雪地的漠河站到椰风阵阵的三亚站,全国到底散落着多少座火车站?
我们每天刷着12306的站点列表,按首字母检索目的地,却很少有人深究——这个列表里的车站,是不是就是全国的“全部家底”?今天咱们就顺着12306的线索,揭开火车站数量的小秘密。
01 站点数据来源:一个公开的前端 JS 文件
常买火车票的人都知道,12306官网的“国内站点”列表是查询车站的重要入口,输入首字母就能拉出一串相关车站。但这个列表背后,藏着更完整的车站数据。
只要打开浏览器的开发者模式(按下F12即可),在网络请求里就能找到一个特殊的JS文件——station_name_new_v10092.js,地址:https://www.12306.cn/index/script/core/common/station\_name\_new\_v10092.js。
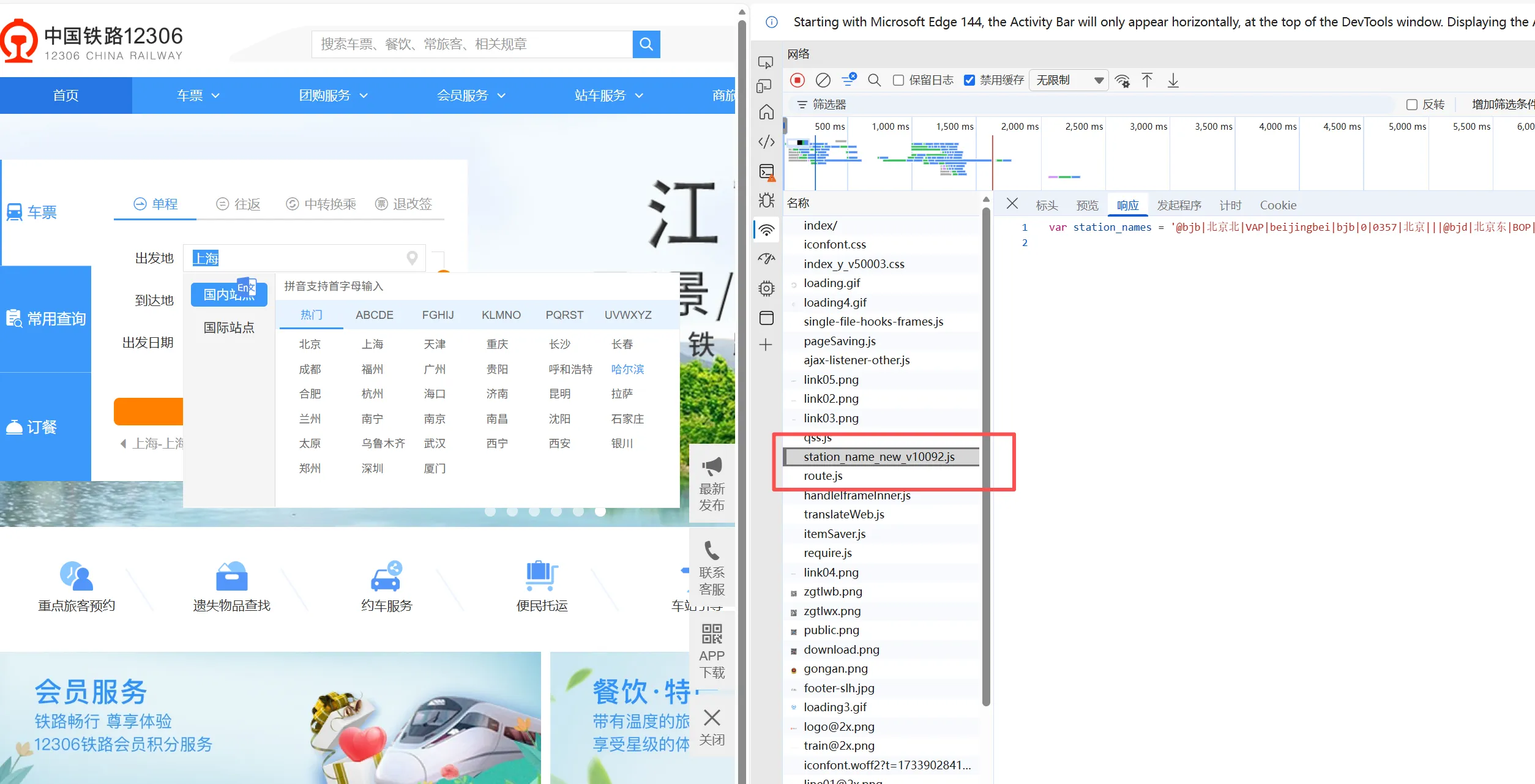
这个文件里没有复杂的代码,只有一个名为station_names的变量,而变量里存储的,正是一长串用特殊符号分隔的车站信息。随便截取一段都能看到规律:
@bjb|北京北|VAP|beijingbei|bjb|0|0357|北京|||@bjd|北京东|BOP|beijingdong|bjd|1|0357|北京|||@bji|北京|BJP|beijing|bj|2|0357|北京|||
字段依次代表:站名简码、中文站名、电报码、拼音、简拼、序号、区号、所属城市等。其中电报码(如 VAP)是铁路系统内部使用的唯一识别符,具有较高的数据准确性。
从结构上看,这份文件可视为一部标准化的铁路客运车站字典。
02 全国到底有多少座火车站
有了结构化数据,下一步就是用Python做数据提取与统计。核心逻辑是“分割-过滤-存储”:先用“@”分割出单条车站记录,过滤掉空值(字符串首尾可能存在空字符),最后统计有效记录数并导出为CSV,方便后续分析。
pythonstation_names = 'JS文件里的车站信息字符串'
# 按@分割数据,统计有效车站数量
station_name_list = station_names.strip().split('@')
print(f"车站总数:{len([s for s in station_name_list if s])}")
# 导出为CSV文件
with open('station_name.csv', 'w', encoding='utf-8') as f:
for station_str in station_name_list:
if not station_str:
continue
station_info = station_str.strip('|').split('|')
f.write(','.join(station_info)+'\n')
运行代码后,答案出来了——3379座。这个数字是不是就是全国火车站的“标准答案”?
还真不是。上海的朋友可能有过这样的经历:乘坐S1601次市域铁路动车时,会经过莘庄、春申、新桥、车墩等站点,但在12306的“国内站点”列表里,你根本查不到这些车站的身影。
更有意思的是,12306官网上明明能查到S1601次的完整时刻表,清晰标注着这些“隐形站点”的停靠信息,可它们就是不在车站检索列表里。这就矛盾了——为什么有的车站能卖票却“查无此站”?
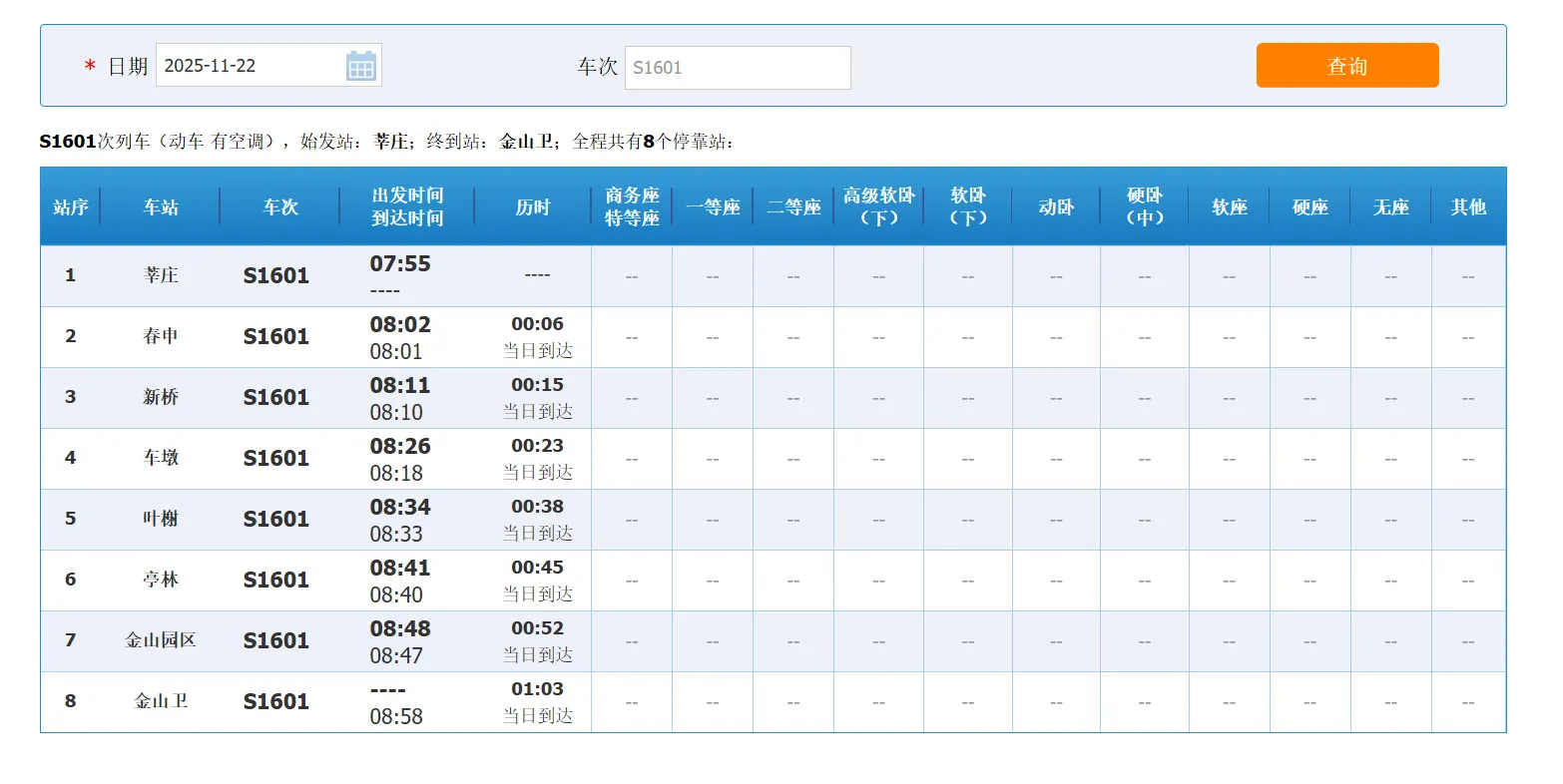
为什么会有“漏网之鱼”?
其实问题出在“统计范围”上。12306的station_names变量,本质上是“办理全国铁路跨局旅客运输业务的车站清单”,主要覆盖普速铁路、高铁干线的客运车站。
而像上海S系列这样的市域铁路,定位是“城市通勤铁路”,主要服务于同城或邻近城市的短途出行,很多时候由地方铁路部门运营管理。这类车站的服务范围、票务系统对接方式都和干线铁路不同,因此暂时没有纳入12306的统一站点检索列表,但这并不影响列车售票和运行。
除了市域铁路站点,还有一些小型会让站、乘降所(仅办理少量旅客上下车的站点),以及正在新建、尚未正式开通的车站,也不会出现在这份清单里。如果把这些都算上,全国火车站的实际数量会比3379座多不少。
如果让你做一个12306,你会怎么设计数据库
有了结构化的车站字典,可以进一步构建完整的铁路数据体系。后续将从数据库角度出发,设计一个简化版的铁路客运查询系统,包括:
- 车站字典
- 车次信息
- 列车时刻表
使用 PostgreSQL 进行表结构设计,配合 FastAPI 提供查询接口,实现按日期与车次获取停靠站、到发时间等功能。
在此基础上,还可扩展以下应用场景:
- 利用相册中的火车票照片,通过 OCR 与站点字典校准,提高识别准确度
- 根据历史车票构建个人铁路出行记录
- 统计累计乘车时间、经过的城市数量、行程里程等数据
从而为用户的出行留下更完整、可量化的记录。
本文作者:司小远
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!